The syntax
Syntax in the Japanese language comes in several parts. From the lowest to the highest, we see the kana and kanji, used to compose words, which are used to compose sentences, which in turn function as the building blocks of the spoken and written language. We will look at each of these "blocks" in order, and look at how they all come together to form the Japanese language.
The kana
The basics
What the alphabet is to western languages, the 五十音, "gojuuon", is to Japanese. This Japanese syllabary is a collection of 46 syllables (roughly half of which have 'voiced' counterparts) that act as phonetic building blocks in the Japanese language. Arranged in the traditional way, and read top-down, right-to-left, these 46 syllables can be written in either of two scripts: hiragana and katakana:
| ん | わ | ら | や | ま | は | な | た | さ | か | あ |
| (ゐ) | り | み | ひ | に | ち | し | き | い | ||
| る | ゆ | む | ふ | ぬ | つ | す | く | う | ||
| (ゑ) | れ | め | へ | ね | て | せ | け | え | ||
| を | ろ | よ | も | ほ | の | と | そ | こ | お |
| ン | ワ | ラ | ヤ | マ | ハ | ナ | タ | サ | カ | ア |
| (ヰ) | リ | ミ | ヒ | ニ | チ | シ | キ | イ | ||
| ル | ユ | ム | フ | ヌ | ツ | ス | ク | ウ | ||
| (ヱ) | レ | メ | ヘ | ネ | テ | セ | ケ | エ | ||
| ヲ | ロ | ヨ | モ | ホ | ノ | ト | ソ | コ | オ |
Transcribing these tables into western, and more specifically English, sounds, the table looks roughly as follows:
| n | wa | ra | ya | ma | ha | na | ta | sa | ka | a |
| (wi) | ri | mi | hi | ni | chi | shi | ki | i | ||
| ru | yu | mu | fu | nu | tsu | su | ku | u | ||
| (we) | re | me | he | ne | te | se | ke | e | ||
| (w)o | ro | yo | mo | ho | no | to | so | ko | o |
These tables seem to contain 48 syllables instead of 46, but the two syllables 'wi' and 'we', (ゐ/ヰ and ゑ/ヱ) have not been in use since the Japanese language was revised following shortly after the second world war. They have been included here only for completeness, and in modern Japanese do not appear in the syllabaries table. The を is still very much in use, but only as a grammatical particle that is pronounced as お, and so the only accurate transcription is as 'o'. However, in names it may be pronounced as 'wo', and so we find the consonant in parentheses in the table of transcriptions.
We can look at these tables in two ways. Firstly, as arrangements in columns. When doing so, the first column (going right to left rather than left to right) is called the あ—column, the second column the か—column, and so forth. We can also look at them as arrangements of rows, in which case the first row is called the あ—row, the second one the い—row, followed by the う—, え— and お—rows. Thus, the katakana symbol メ for instance can be found on the え—row of the ま—column.
Some of these columns have 'voiced' variants. Voicing is a linguistic term used to indicate consonants that are pronounced with air running past the vocal cords. In Japanese, the か-, さ-, た- and は—columns (ka, sa, ta and ha) can be given a special :diacritic mark, called 'dakuten' (だくてん濁点) to indicate they are voiced rather than plain, changing their pronunciation:
| ば/バ | だ/ダ | ざ/ザ | が/ガ |
| び/ビ | ぢ/ヂ | じ/ジ | ぎ/ギ |
| ぶ/ブ | づ/ヅ | ず/ズ | ぐ/グ |
| べ/ベ | で/デ | ぜ/ゼ | げ/ゲ |
| ぼ/ボ | ど/ド | ぞ/ゾ | ご/ゴ |
Which is transcribed as:
| ba | da | za | ga |
| bi | dzi | ji | gi |
| bu | dzu | zu | gu |
| be | de | ze | ge |
| bo | do | zo | go |
A note about 'dzi' and 'dzu': while these are technically the correct transcriptions for ぢ and づ, these syllables have been rendered obsolete in current Japanese, with words that used to use ぢ now using じ, and words that use づ now using ず. This will be explained in a bit more detail in the section on pronunciation.
In addition to this regular voicing, the は—column has a secondary voicing, indicated with a small circle diacritic mark, called 'handakuten' (はんだくてん半濁点), which rather than producing a 'b' sound, produces a 'p' sound:
| ぱ/パ | pa |
| ぴ/ピ | pi |
| ぷ/プ | pu |
| ぺ/ペ | pe |
| ぽ/ポ | po |
Writing the kana
Both hiragana and katakana may be relatively simple scripts compared to the complex Chinese characters also in use in Japanese, but they both have specific ways of writing each syllable. The following tables show how to write both hiragana and katakana the proper way. Note that these written versions look different in places from print form.


Pronouncing Japanese
Pronunciation wise, each of these syllables is equally long. This is traditionally explained by referring to the pronunciation of Japanese as mora, a linguistic term meaning "the time required to pronounce an ordinary or normal short sound or syllable". In Japan, this concept of mora is usually explained with the easier concept of drum beats: each basic syllable is one beat long, with certain combinations of kana lasting one and a half or two beats.
The vowel sounds of Japanese, あ, い, う, え and お do not all have English equivalents; あ is actually identical to the initial vowel sound in "I" or "eye" — that is, the 'a' sound without the finalising 'i' sound. The い is a little easier, sounding like the 'ee' in 'creep'. The う is particularly annoying, because there is no English equivalent. It is identical to the vowel sounds of properly Scottish 'you' or 'do', or the Dutch open 'u' such as in 'huren'. え is pronounced like in the English 'help', and the お, finally, is pronounced like the 'o' in 'or'.
While for most kana the consonant sound is reasonably approximated by the transcribed consonant as listed in the earlier tables, there are a few notable exceptions. For instance, while romanised as "hi", ひ/ヒ is usually pronounced with a consonant that doesn't sound like an 'h', but more like the German or Scottish "ch" as found in German words such as "ich" (meaning "I") and Scottish words such as "loch" (meaning "lake").
Also in the は-colum, the syllable ふ/フ does not have an 'h' as consonant sound, or even the 'f' consonant sound that it is typically transcribed with, but rather uses only pure aspiration as initial sound. This is mostly unknown in western languages, and will be the hardest to get right for people starting out with Japanese. Rather than being formed in the mouth, the syllable ふ starts being formed at the diaphragm, while breathing out. Paired with the lips shaped as if casually blowing out a match or candle (rather than tightened for whistling), this rush of air is then given a vowel sound, and the syllable is complete.
In the つ—column we also see an interesting pronunciation 'quirk': while ち and つ, strictly speaking, have voiced versions, written ぢ and づ, over the years the difference in pronunciation between ぢ and じ, and づ and ず, has all but disappeared, leading to an official move towards replacing these ぢ and づ with じ and ず entirely. However, there are (quite a number of) exceptions to this move for replacement: if the two first kana of a word are the same, but the second one is voiced, the same kana are used (for example, つづく and ちぢめる). Also, in compound words in which voicing occurs, the original kana form is used (for instance, かた片 + つ付く → かたづ片付く and はな鼻 + ち血 → はなぢ鼻血). This exception only applies when the compound word can be considered a combination of words. Both 片付く and 鼻血 derive their meaning from their constituent words, but in a word like いなずま稲妻, meaning "lightning", the first kanji refers to rice plants, and the second kanji refers to (someone's) wife. In these words, even if the affixed compound would normally have a つ or ち, the voicing is written as ず or じ in modern Japanese, rather than づ or ぢ.
That said, voicing in compound nouns is a bit strange in that there are no rules to tell when something will, or will not voice, so the best strategy — which applies to learning words in general anyway — is to learn words as word first, then learn them as combinations, rather than the other way around.
Finally, the ら—column can be a problem because for most western listeners, different people will seem to pronounce the initial consonant in this column differently. While in many western languages the consonants "d", "l", and "r" are considered quite distinct, in Japanese this distinction is far less; any syllable starting with a consonant ranging from a full fledged "l" to a rolling Spanish "r" will be interpreted as a syllable from the ら—column, with the "standard" pronunciation being somewhere between a "d" and an "r".
Not pronouncing Japanese
This sounds like an oddly named section, but some bits in written Japanese are actually not really pronounced at all. In fact, not infrequently you will hear Japanese that does not seem to reflect the written form, with the verb "desu" seemingly being pronounced "des", the adjective "hayaku" seemingly being pronounced "hayak", the command "shiro" seemingly being pronounced "sh'ro", and many more of such vocal omissions.
In fact, many syllables with an い— or う—sound tend to have these vowel sounds left almost unpronounced. I say almost, because the vowel sound is typically preserved by virtue of the consonants used. For instance, the word そして, transcribed as 'soshite' is typically pronounced in such a way that it can be considered transcribable as "sosh'te" instead. However, forming "sh" means also forming a pseudo-vowel sound. In fact, even in this "omitted vowel" there is room for variation, so that a "sh" can sound like it was supposed to become "shi" or "shu", and it is this feature that is exploited quite heavily in Japanese.
This leads to a small problem. Because it sounds like the vowel is entirely missing, you might be tempted to mimic this sound, but end up genuinely omitting the vowel entirely because that's what your ears — which are not yet accustomed to Japanese phonetics — think is happening. However, this also makes your Japanese highly unnatural, because to a Japanese ear the vowel is only mostly omitted, not entirely.
The problem then is one of hearing: when learning a new language it is important to "unlearn" how to hear language. Much like how we have learned to see the world in a way that it's actually not (you will consider a brown table with a light shining on one end, brown, instead of brown on one end, and a completely different colour where the light is hitting it), as infants we learn to disregard any and all sounds that don't feature in the languages we're raised with. As such, remarkable as this may sound, we unlearn how to hear things accurately, and instead learn how to map what we hear to what we know the language is supposed to sound like. While highly effective when learning a language, or a family of languages with similar pronunciations, it's disastrous when learning a language that has a different phonetic system.
The best advice with regards to this is to simply listen to a lot of Japanese. It takes time and effort to unlearn the unconscious mapping your brain does for you. You're going to get it wrong, but as long as you know you are, you'll be on the right track.
Hiragana and katakana differences
If hiragana and katakana sound exactly the same, why then are there two different scripts?
When the Japanese first developed a written system, it was based on the characters used in China for the Chinese language, in which for the most part the meaning of the characters were subservient to what they sounded like: if a word had an "a" sound in it, then any Chinese character that sounded like "a" could be used for it, without any real regard for its meaning. This "using certain characters for their sound only" became more widespread as the number of characters per syllable dropped from quite many to only a handful, and as writing became more widespread two syllabic scripts developed. One, which simplified phonetic kanji by omitting parts of them lead to what is today called katakana. Another, which simplified phonetic kanji by further and further reducing the complexity of the cursive forms for these kanji, has become what is known today as hiragana. We can see this illustrated in the next figure, which shows the characters the hiragana came from, and the highly stylistic cursive form characters had, highlighting the degree of simplification that cursive writing brought with it.
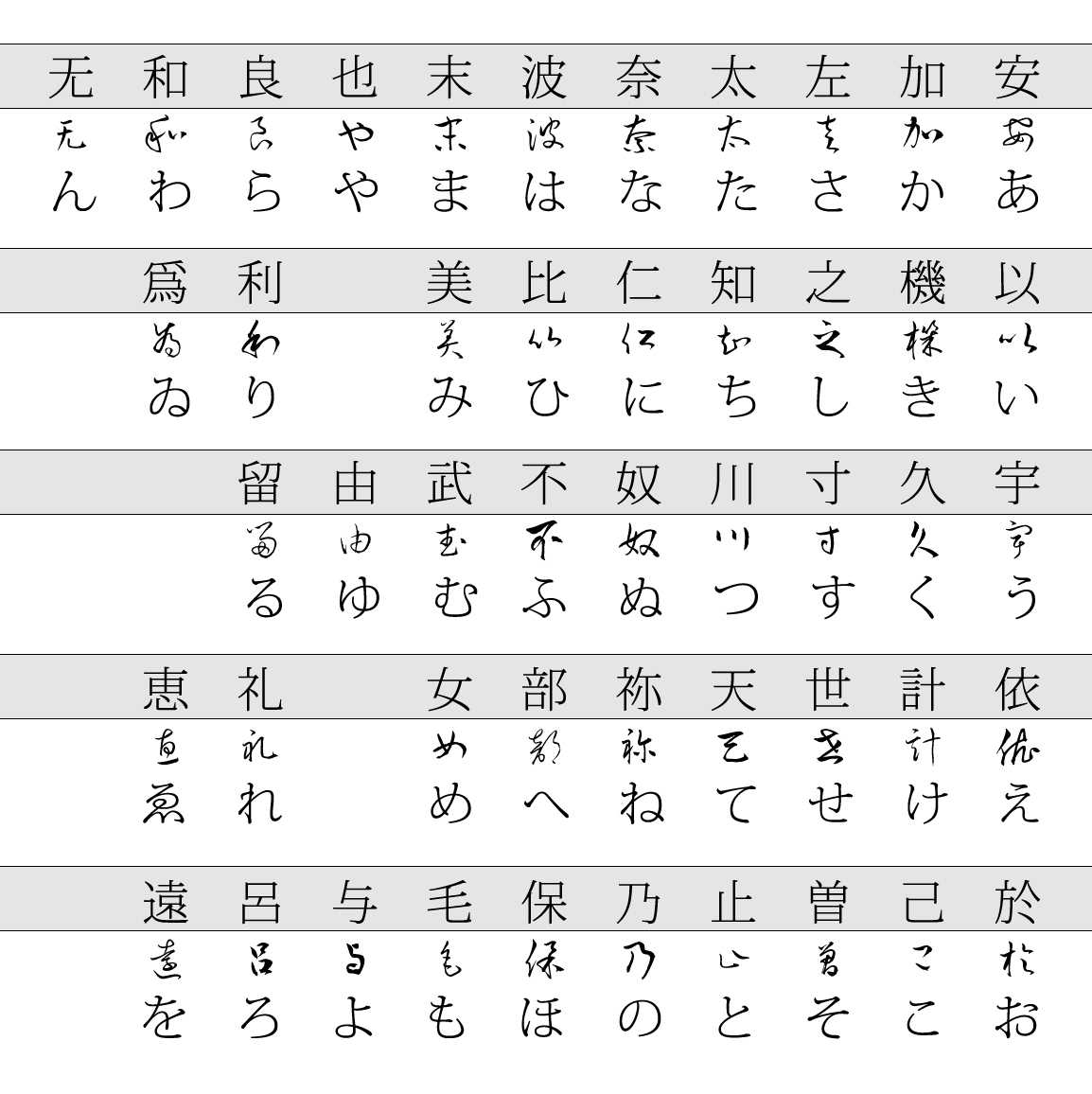
Katakana got a slightly different treatment, in that these are actually fragments of characters, rather than stylistic simplifications. The second derivations figure illustrates this, with a note that the fragments were lifted from handwritten characters, so that the "logic" is mostly found in the cursive line of characters.
These two scripts have differed in roles throughout history, and in modern Japanese hiragana is used for anything Japanese that does not use (or need) kanji, and katakana is used in the same way that we use italics in western language, as well as for words that have been imported into Japanese from other languages over the course of history. The only genuine difference between the two scripts is the way in which long vowel sounds are written, as we shall see in the next section.

Writing spoken japanese
Using the kana as basic building blocks, Japanese pronunciation consists of a few more things beyond basic syllables: in addition to "simple" syllable sounds, it contains long vowels, glides and double consonants.
Long vowels, contrary to the name, do not always mean "the same vowel, twice as long". Strictly speaking, a long vowel in Japanese is a combination of two vowels, pronounced over two "drum beats". In katakana, long vowels are really just that, a vowel with a dash to indicate the sound has been doubled in length, but in hiragana the doubling is different. Of the five basic Japanese vowel sounds (あ, い, う, え and お) the first three have fairly simple long vowel counterparts in hiragana, simply doubling in writing, but the latter two are more complicated, having two different written forms:
| hiragana | katakana | |
|---|---|---|
| あ | ああ | アー |
| い | いい | イー |
| う | うう | ウー |
| え | ええ, えい | エー |
| お | おお, おう | オー |
While the pronunciation for ああ, いい and うう are intuitive (same sound, twice as long), the pronunciations for ええ, えい, おお and おう and more subtle. The first, ええ, may be pronounced as a "same sound, twice as long" え, but may also be pronounced as えい, which is similar to the '-ay' in the English 'hay'. For おお, the pronunciation is like "oa" in "oak", with おう often sounding the same, but when pronounced slowly, having a distinct hint of "u" at the end.
This doubling is the same for syllables with consonant sounds, so that for instance vowel doubling for the syllables from the ま—column look as follows:
| hiragana | katakana | |
|---|---|---|
| あ | まあ | マー |
| い | みい | ミー |
| う | むう | ムー |
| え | めえ, めい | メー |
| お | もお, もう | モー |
In addition to long vowels, Japanese words may contain "glides". Being considered contractions of い—row syllables with any one of the three syllables や, ゆ and よ, glides are written as the い—row syllable, normal sized, and then the や, ゆ or よ syllable at either half height (for horizontally written Japanese) or half width (for vertically written Japanese). To illustrate:
| kana | pronunciation | as glide | pronunciation | ||
|---|---|---|---|---|---|
| き + や | きや | kiya | きゃ | kya | |
| し + ゆ | しゆ | shiyu | しゅ | shu | |
| ち + よ | ちよ | chiyo | ちょ | cho | |
| み + や | みや | miya | みゃ | mya | |
| ひ + よ | ひよ | hiyo | ひょ | hyo | |
| に + ゆ | にゆ | niyu | にゅ | nyu | |
| り + よ | りよ | riyo | りょ | ryo |
While a written combination of two syllables, the glide it represents is only a single "drum beat" long, just as the regular syllables. Thus, the word キャンプ is three beats long: spelled out, it will be pronounced きゃ, ん and ぷ.
Finally, the last feature of spoken Japanese reflected in writing is what is known as the "double consonant": a reasonably recent change to the way Japanese is written (in the sense that this change occurred sometime during the medieval period, when written Japanese had been around for a little under a millennium) which indicates that a particular consonant has a short pause before it is actually pronounced. This consonant doubling is found in a number of western languages as well, such as in Italian, where words like 'tutti' have a written double consonant while in terms of pronunciation there is simply a pause before the consonant. In Japanese, because there are no actual 'loose' consonants, the doubling is represented by a special character: a つ (or ツ) written either half height (in horizontal writing) or half width (in vertical writing) to indicate the pause. To illustrate the difference between this small つ/ツ and the regular form, a few example words:
| small っ | pronunciation | meaning |
|---|---|---|
| はっか | "hakka" | ignition |
| しっけ | "shikke" | humidity |
| まっか | "makka" | intensely red |
| normal つ | pronunciation | meaning |
|---|---|---|
| はつか | "hatsuka" | 20 days/20th day |
| しつけ | "shitsuke" | upbringing |
| まつか | "matsuka" | the 'Pine' family of trees |
This "つ/ツ as a pause" is also applied when a :glottal stop is needed in for instance an exclamation, "あっ!", which is an exclamation with a "cut off" rather than long vowel sound.
Katakana specific
As katakana has been used to write out words imported from other languages into Japanese, it has a few extra "rules" that do not apply to written hiragana, including a number of ways to produce normally "illegal" syllables: syllables that do not fit in the Japanese table of syllables, but are found in foreign words nonetheless. Examples of these are for instance the initial syllable "fi" in the English word "fire", or the "swe" in "Sweden".
The table of approximating writing is as follows, observing English pronunciation rules (combinations with normal Japanese orthography are omitted):
| a | e | i | o | u | |
|---|---|---|---|---|---|
| ch | チェ | ||||
| d | ディ | ドゥ | |||
| f | ファ | フェ | フィ | フォ | |
| fj | フィオ | ||||
| j | ジェ | ||||
| q | クァ | クェ | クィ | クォ | ク |
| s | セィ | ||||
| sh | シェ | ||||
| sw | スァ | スェ | スィ | スォ | スゥ |
| t | ティ | トゥ | |||
| v (1) | ヴァ | ヴェ | ヴィ | ヴォ | ヴ |
| w | ウェ | ウィ | ウォ | ウ | |
| x | ックサ | ックセ | ックセィ | ックソ | ックス |
| y | イェ | イ | |||
| z | ゼィ |
Note that 'wo' is not ヲ (as that is pronounced お), and that for the 'x' series, the leading ッ is the consonant doubling symbol.
In addition to these, there are also a number of consonants which, in terms of pronunciation, already have Japanese counterparts:
| consonant | column |
|---|---|
| c, pronounced as 's' | uses the さ—column |
| c, pronounced as 'k' | uses the か—column |
| l | uses the ら—column |
| v (2) | uses the ば—column. Preferred to 'v (1)' in the above table. |
Due to the fact that most loan words have come from some specific language, many of which are not English, Japanese loan words may have a different written form than expected. For instance, Brussels is written as ブリュッセル, "buryusseru", rather than ブラセルズ, "buraseruzu", and English (the people) is written as イギリス, "igirisu", rather than イングリッシュ, "ingurisshu".
Punctuation and writing
Of course, in addition to a "letter" script, there is :interpunction — symbols that indicate pauses, stops, quotes and other such things. In Japanese, the following punctuation symbols are common:
| symbol | |
|---|---|
| full stop | 。 |
| comma | 、 |
| single quotes | 「 and 」 |
| double quotes | 『 and 』 |
| parentheses | ( and ) |
| kanji repeater | 々 |
| separators | ・ and = |
| drawn sound | ~ |
| ellipsis | ... (usually written twice: ......) |
Less used, but always good to have seen are the following:
| symbol | |
|---|---|
| idem dito | 〃 |
| hiragana repeaters | ゝ, ゞ |
| katakana repeaters | ヽ, ヾ |
| kanji sentence finaliser | 〆 |
And then there are western punctuations which have Japanese counterparts, but tend to be expressed differently instead:
The symbol ? is written the same way as in English, but typically the particle か is used instead. This particle か serves both as question mark, as well as a marker for parts of a sentences, indicating they are questioning instead of stating. Similarly, the symbol ! is written the same way as in English, but typically exclamations are simply avoided. Instead, emphasis particles such as よ or わ may be used for effect, but these do not signify real exclamation.
Finally, not quite interpunction but important nonetheless are the two ways to emphasise parts of written language in the same way we use bold or underlining in western composition: dotting and lining. In horizontal writing, words will have dots over each syllable or kanji, or a line over the entire emphasised section. In vertical writing, the dots and lining is placed on the right side of text.
In addition to knowing the basics about which symbols can be used, Japanese (as well as some other Asian languages such as Chinese) has the unique problem of deciding in which direction to write. For all its modernising, some things such as direction remain unchanged. As such, for the most part printed Japanese (as well as handwritten material) is written top down, right to left. In contrast, most Japanese material on the internet is typically written in a western fashion, with the text running left to right, top to bottom.
To make matters more interesting, in recent history, Japanese could also be written horizontally right-to-left. This practice has pretty much disappeared except in shipping (ship names may still be written in this way) and for 'older style' shop signs. You will not encounter full texts written in this way in modern or even just post-Meiji older Japanese.
There are a few differences between horizontal and vertical writing, most notably in terms of where to place half size characters and interpunction:
| horizontal | vertical | |
|---|---|---|
| half size characters | half-height | half-width, right aligned |
| comma, full stop | lower left: [、], [。] | upper-right: [︑], [︒] |
| opening quotes | corner in the upper left (「) | corner in the upper right (﹁) |
| closing quotes | corner in the lower right (」) | corner in the lower left (﹂) |
| parentheses | left and right: i.e. ( and ) | above and below: i.e. ⁀ and ‿ |
| dotting | above characters | to the right of characters |
| lining | above characters | to the right of characters |
| drawn sound, hyphen | horizontal (〰, ―) | vertical ( ︴,︱) |
| ellipsis | horizontal (...) | vertical (⁝) |
Kanji
One of written Japanese's most well-known features is that it comprises three writing systems: the two kana scripts, and a third script called kanji, translating as "Chinese characters", which are ideographs that over the course of history made their way from China to Japan. One of the biggest problems with kanji is that there aren't just many, but each one can have a multitude of pronunciations dependent on which words the kanji is being used for. To look at why this is, a brief history of how modern Japanese got the kanji that are used today is in order.
Early Japanese evolved as a purely spoken language. Without a written form, indeed seemingly without having discovered writing at all, the first instances of writing in Japan were in fact not Japanese at all, but Chinese: after having come into contact with the Chinese and their intricate writing system, writing in early Japan (circa the late sixth century) was restricted to immigrant scribes, who wrote official records in Chinese. While initially a rarity, the Taika reform of the mid-seventh century changed all that.
Reforming Japan to a more Chinese inspired state, based on centralisation of government and Confucian philosophy, the need for a state clergy transformed the largely illiterate Japanese society to one with literacy as an essential part of court and intellectual life. The prestigious rank of scribe became a hereditary rank, and so as generations of scribes came and went, the Chinese that was used slowly drifted away from proper Chinese, and more towards a hybrid style of Chinese and the form of Japanese as it was used at the time. However, the readings used for Chinese characters were more or less fixed, and the readings that survive from that period are known today as ごおん呉音, go'on, readings.
Then, in the seventh and eighth century, during the Chinese Tang dynasty, there was another cultural exchange between Japan and China, leading to a second influx of readings for Chinese characters. As China changed rulers, so too did the dominant dialect for the Chinese language, and the readings that were brought back to Japan from this second exchange were in some cases radically different from the initial readings the Japanese had become familiar with. Readings for kanji from this period are known as かんおん漢音, kan'on, readings.
Finally, in the fourteenth century, during the most famous of Chinese dynasties — the Ming Dynasty — there was another influx of Chinese. This influx came from two fronts: firstly, the merchants doing business with the Chinese brought back home readings that are referred to as とうおん唐音, tō'on, and secondly from Zen monks who went to study Zen Buddhism in China and brought back readings that are referred to as そうおん宋音, sō'on. Rather than a single exchange, this was an ongoing effort, and so 唐音 readings tend to span from the late thirteenth century to well into the Edo period (えどじだい江戸時代, edojidai), also known as the Tokugawa period (とくがわじだい徳川時代, tokugawajidai), named after the first Edo shogun Tokugawa Ieyasu (とくがわ徳川いへやす家康), which lasted until the late nineteenth century.
The naming for these readings, however, can be slightly confusing. 呉音 readings are known as "wu" readings. However, this name does not refer to the Wu dynasty (which spans the first two centuries a.d.) but simply to the region the readings are believed to have come from (呉 being the name of the Wu region in Jiangnan, 江南, in modern China). The 漢音 readings are called "han" readings, but have essentially nothing to do with the Han Dynasty, which spanned the late third century BCE.
The 唐音 readings, equally confusing, are referred to as Tang readings, even though this name would be more appropriate for the 漢音 readings, which actually derive from Tang Chinese. Rather, 唐音 derive their readings from Chinese as it was used during the Sung dynasty and onward.
In addition to these changes to Chinese readings, the written language itself slowly moved away from Chinese proper, through a Chinese-Japanese hybrid written language, to what is essentially the Japanese we know today: mixed Chinese characters with syllabic script (itself derived from Chinese characters being used phonetically) with different readings for Chinese characters typically indicating different interpretations of the characters used.
While there had been no written language before the introduction of Chinese, there had certainly been a language, which survived throughout the ages by virtue of the commoners not needing to bother with writing, and thus not incorporating Chinese into their language as much as royals and officials would. This eventually led to native Japanese pronunciation being applied to written Chinese, giving us two different reading "systems": the おんよ音読み, "on'yomi", which are the Chinese derived readings, and the くんよ訓読み, "kun'yomi", which are the native Japanese derived readings.
A major problem with kanji is that without a knowledge of the kanji in question, it is not always clear when to use which reading. There are no rules that state that certain kanji are read in a particular way when used on their own, or when part of a word, and so the only real way to make sure you are using the right reading for a kanji is to look it up and then remember the reading for the context the kanji was used in.
This usually leads to the question of why kanji are still being used, when other languages only use phonetic scripts. The Japanese abstracted syllabic scripts from Chinese for phonetic writing, so why the continued reliance on kanji? While it seems odd that Chinese characters are still being used in a language that also has a phonetic script, the main reason it still uses Chinese characters is because of a key aspect of the Japanese language: it is homophonic.
Words in the English language, for instance, are essentially distinct. While there are a number of words that sound the same but mean different things, the vast majority of words in the English language only mean one thing. In Japanese we see quite the opposite: there are only 71 distinct single syllable sounds, but there are close to 300 words which can be written using a single syllable. It is easy to see that this means that for any single syllable word you can think of, there will be (on average) at least three other words that you can write in exactly the same way. How do you know which is meant if you don't use kanji or additional notes?
For two syllable words, we see the same thing; there are a bit over 2000 combinations possible when using two syllables (not all combinations of two syllables are actually used in Japanese) but there are over 4000 words with a two syllable pronunciation. That means that on average, for every two syllables you write, you can be referring to one of two words. Even with three and four syllables, the problem persists, with a greater number of words available than there are possible readings.
Because of this, Japanese is known as a "homophonic" language - a language in which a large number of distinct words will share the same pronunciation. For instance, a word pronounced "hare" can refer either to 'fair weather', or a 'boil/swelling'. The word "fumi" can mean either 'a written letter', or 'distaste'. The word "hai" can mean either 'yes', 'actor', 'ash', 'lung' or 'disposition', and that doesn't even cover all possible words that are pronounced similarly: without the use of kanji, it would be incredibly hard to decipher written Japanese.
Of course, one can argue that spoken Japanese doesn't rely on kanji, so it must be possible to do away with them in the written language too, but this ignores the fact that just because a simplification can be made, it might make things harder in other respects. For instance, there are no capital letters, spaces, full stops, or all those other syntactic additions in spoken Western languages either, and yet we still keep those in for ease of reading. Similarly, the use of kanji has clear benefits to Japanese as a written language: they act as word boundary indicators, allow readers to get the gist of a text by quickly glossing over them, and solve the problem of needing to apply contextual disambiguation all the time like one has to in spoken Japanese.
However, just because they are useful, there have been "improvements" in terms of their use in written Japanese. At the turn of the 20th century, written Japanese was as complicated as written Chinese in terms of kanji use, and even more complicated as a written language on its own, because kana did not reflect pronunciation. In this Japanese, a word written as 'sau' would be pronounced as a long 'so', and something like 'kefu' would instead be pronounced as a long 'kyo'. When, after the second world war, the Japanese ministry of education reformed the written language, they didn't just get rid of this discrepancy between written and spoken Japanese, they also got rid of some 7000 kanji, restricting the number of kanji to be used in daily life to around 3500, and designating a set of less than 2000 kanji as part of general education (initially known as the とうよう当用, 'touyou', kanji, and after refinement to the set in 1981, became known as the じょうよう常用, 'jouyou', kanji). This still sounds like a lot, but given that the average English speaker knows around 12,000 words, with academics knowing on average anywhere up to 17,000 words, having to know 2000 kanji in order to understand the vast majority of your written language isn't actually that much.
Types of Kanji
One of the things that one notices after having looked at kanji for a while is that a great number of kanji use a great number of simpler kanji as their building blocks. Similar to how kana syllables can be combined to form words, kanji have throughout history been combined to form more complex kanji, and complicated kanji have been reduced to combinations of simple kanji for the sake of remembering them, as well as organising them.
Traditionally, kanji are organised in four classes, and two categories, following the convention that was introduced in the very first comprehensive Chinese character dictionary, at the beginning of the Western calendar's second century. The four classes relate to the way in which characters are composed:
- Pictographs (しょうけいもじ象形文字, shoukeimoji) — Hieroglyphic characters that look like what they mean (numbers 一, 二, 三, or 山 for 'mountain')
- Ideographs (えもじ絵文字, emoji) — Characters that represent things in some visual way, divided into two subclasses:
- Simple ideographs (しじもじ指事文字, shijimoji), such as 上 and 下 (for 'above' and 'below' respectively), and
- Compound ideographs (かいいもじ会意文字, kaiimoji), such as 休, 'rest', consisting of the compounds 人, 'person', next to 木, 'tree')
- Form/Reading combinations (けいせいもじ形声文字, keiseimoji) — These characters combine two kanji into a single character, with one of the two indicating a root meaning, and the other indicating (at least one of) the reading(s) for the character.
The two categories are related to how characters are actually used:
- Derivatives (てんちゅうもじ転注文字, tenchuumoji) — These are characters of which the meanings are derivations, or extensions, of the character's original meaning.
- Phonetic loans (かしゃもじ仮借文字, kashamoji) — These are characters which are used purely phonetically, ignoring their original meaning, or characters that are consistently used "wrongly". This class includes those kanji that had to be made up "on the spot" in order to accommodate words and concepts imported into Japanese from foreign languages for which no pre-existing kanji form was available.
To make matters even more interesting, there are also characters which fall in either the third or fourth class, but for which certain meanings have become tied to certain readings. An example of this is the character 楽, which can mean "music" when pronounced as "gaku", but mean "comfort" or "enjoyment" when pronounced as "raku".
Writing Kanji
Writing kanji follows relatively strict rules. Because kanji are mostly composed of smaller kanji, there is a uniform way of writing that allows people to remember kanji as combinations of simpler kanji, rather than as combinations of strokes that only once finished, form a kanji. There are a limited number of strokes that are used for drawing kanji.
straight strokes
| stroke | drawing order | examples |
|---|---|---|
| 一 | left to right | 二, 三 |
| ㇀ | starting at the lower left | 冫 |
| 丶 | called a "tick mark", starting upper left | 冫, 丸, 犬 |
| ㇏乀 | starting at the top | 乂, 又 |
| 丿 | starting at the top | 乂 |
| 丨 | starting at the top | 十 |
| 亅 | starting at the top, with a serif to the left at the end | 了, 小 |
| ㇁ | starting upper left, and then pulling back at the end | 犭 |
| ㇂ | starting at the top, with an upward serif at the end | 弌, 戈 |
angled strokes
| stroke | drawing order | examples |
|---|---|---|
| ㇄ | top to bottom, then left to right, as one stroke | 兦, 山 |
| ㇅ | left to right, then top to bottom, then left to right | 凹 |
| ㇇ | left to right, then a hook curving down left | 水 |
| ㇆ | left to right, then top to bottom with a serif to the upper left | 刀, 方 |
| 𠃍 | left to right, then top to bottom | 囗 |
| 乚 | top to bottom, then left to right with a serif upward at the end | 礼 |
| 乁 | top left to right, then down right with an upward serif at the end | 虱,丮 |
multi-angled strokes
| stroke | drawing order | examples |
|---|---|---|
| ㇉ | top to bottom, then the same as ㇆ | 丂 |
| ㇈ | top left to right, then the same as 乚 | 九 |
| ㇋ | top left to right, top to bottom, then the same as ㇇ | 乃, 廴 |
| ㇌ | a connected stroke consisting of ㇇ and ㇁ | 阝 |
Composition
Several compositional rules apply when a kanji consists of more than one stroke:
- Strokes that do not intersect each other, follow each other in a top to bottom, left to right fashion.
- Kanji used to form more complex kanji also follow this rule. For instance, 乴 is written as first 折, which in turn is first 扌, then 斤, and then 乙 is placed underneath.
- When strokes intersect, the following rules apply:
- For a vertical/horizontal intersection where the vertical stroke does not protrude at the bottom, such as in 王, draw the top horizontal first, then the vertical (forming 丅), then the rest.
- For a vertical/horizontal intersection where the vertical stroke does protrude at the bottom, such as in 十, 牛 or 年, draw all horizontals first, and finally the vertical.
- For 乂 crossed strokes such as in 文 or 父, the stroke that runs upper-right to lower-left is drawn first.
- Strokes that intersect complete shapes, such as the vertical in 中 or the horizontal in 母, are written last.
- Box enclosures, such as in 国, are written left|first, then followed up with ㇆ to form 冂, then have their content drawn, and are then closed at the bottom with 一.
- Semi enclosures, such as around 入 in 込 or around 聿 in 建, are written last, after the semi-enclosed component.
There are a few exceptions to these rules (of course), so when learning kanji, one should always have some reference on how to draw kanji.
Reading kanji: furigana
One problem with kanji is that there is no "built-in" way to tell which pronunciation of a kanji is being used. For instance, when a text has the word 行った in it, then it's clear how to pronounce the hiragana part, "tta", but whether the kanji 行 should be pronounced as 'i' or as 'okona' is not clear. The context will help, but sometimes for verbs, and often for nouns, that's not enough to figure out how to pronounce a kanji. Because of this, Japanese has a unique aspect to its written language: furigana.
Furigana, ふ振りがな仮名, literally means "sprinkled kana", and refers to phonetic guide text written over or alongside kanji to indicate the specific reading a reader should use. You have seen several examples of furigana already in this book, where whenever a Japanese term was used involving kanji, its pronunciation was written above it in small lettering. This is not something particular to this book, but a common occurence in Japanese written material, used most often to help the reader disambiguate or pronounce "hard" words, but also for stylistic or even comic effect.
As an illustration of comic effect, one might consider the case of long words that are used with some frequency in a text. These words might only be given two phonetic guide texts throughout the writing: a first time with the 'proper' pronunciation, and a second time with the pronunciation 'are' instead — a pronoun with the contextual meaning "whatever I wrote last time".
While comic effect is perhaps an added bonus to using furigana, it is certainly widely used for stylistic effect. For instance, while the word 首刀 does not exist in Japanese, the kanji mean "neck" and "sword" respectively. A Fantasy novelist could use this "made up" word, and add a phonetic text to note that it should be pronounced as エクサキューシオン・ソード, "ekusakyuushion soodo", a transliteration of the English words "execution sword" into Japanese. While this doesn't make 首刀 a real word, it does allow a writer to paint with words - using the kanji as "pictures" to instil a sense of meaning, and adding an explicit pronunciation so that the sentence can be pronounced as well as written.
Another, even wider used application of furigana is the kind employed in sentences such as あのひと奴がきら嫌い, "I dislike that person". In this sentence, the kanji 奴 is used with the phonetic guide text "hito", meaning "person". However, this is not the real pronunciation of 奴, which is normally pronounced "yatsu", and doesn't just mean "person", but is a derogatory version of the word instead. In essence, while the reading reflects what the speaker is saying, the kanji form of the word expresses what the speaker is actually thinking. This "being able to express both what is being thought and what is being said at the same time" is something that is impossible without this particular feature of written Japanese.
Reading quirks: compound words
As mentioned in the section on kana pronunciations, there's an odd quirk involving the pronunciation of compounds words. This is best illustrated with an example. If we combine the noun 気, "ki", meaning 'spirit', or 'attention', with the verb 付く, "tsuku", to form the compound verb 気付く, then its pronunciation is not "kitsuku". In fact, the second compound voices, leading to the pronunciation being "kidzuku" (or according to modern spelling, "kizuku"). Why this voicing occurs is, sadly, completely and entirely unknown. There are no rules that say when compound words are "supposed" to voice, nor are there any rules we can abstract from all the words that do — any rule that seems to explain half of all voicings that occur in Japanese, seems not to apply to the other half.
The best advice here is simply: "learn compound words as complete words". Even though they can be analysed as compounds, their meaning is typically different from what the compounds individually mean, so learning them as combinations of loose, smaller words, makes very little sense anyway.
Looking up kanji
If we wanted to look up kanji like 枚, 梓 and 檥, then one very obvious feature we see is that all three seem to share a similar structure: 木 to the left, and something else to the right. This is not a coincidence: most kanji can be described as some bit that is used by a number of other kanji, plus a unique part that identifies that particular kanji. The bit of kanji that is shared by several (or in some cases lots of) kanji is called a ":radical", and can be used to look up a kanji if you have no idea what it means or even how to pronounce it.
The very first Chinese character dictionary — the Shuōwén Jiězì (說文解字), published in the year 121 — used 214 such characters as indexing shapes, calling them bùshǒu. (a name that the Japanese copied to the best of their ability, calling them bushu, ぶしゅ部首). While this scheme was thought up almost two millennia ago, amazingly this method of organising kanji has not been fundamentally altered ever since: while written Chinese, and later Japanese, changed over the centuries, the only thing that has really changed is the number of indexing radicals. Current indices list around 400 shapes as radicals, compared to the original 214, mostly due to many shapes being considered "variations" of the classic radicals these days. For instance: while originally only 己 was considered a radical (radical number 49, in fact), Chinese characters have changed over the course of centuries so that now the shapes 已 and 巳 are also used, and are considered variations of the original 己. Kanji that use any of these three shapes may thus be found grouped together.
Some variations on the traditional radicals are simple, such as 牛 changing ever so slightly to become 牜, the only real difference being that the lower horizontal stroke is slanted a little. However, some variations are more drastic, such as 手 becoming 扌; the top stroke has disappeared. The most drastic changes we see, however, are those where a radical is no longer readily recognisable as stemming from a particular kanji. For instance, if you didn't know anything about kanji, you would be hard pressed to imagine that 犭 is actually considered the radical form of 犬. Or that ⺾ in kanji such as 草 is actually the radical form of the kanji 艸. Probably the most confusing of all radicals are the radical forms of the kanji pair 邑 and 阜, which both turn into 阝, but on different sides of kanji: 降 is indexed by 阜, while 部 is indexed by 邑!
Styles
There are several writing "styles" for Japanese, each associated with different uses. The most commonly used style by far is the kaisho, かいしょ楷書, style, or "print" style. Textbooks, novels, newspapers, webpages, virtually all material intended for mass reading consumption uses this style. There are a few different variants of this form, of which the Minchou, みんちょう明朝, and gothic, ゴシック, variants are the most common. The Minchou variant is characterised by fine lines and serifs (the font that was used for the Japanese in this book is a Minchou variant of the kaisho style, for instance), while the gothic variant is characterised by thick, clear lining without any serifs. This variant is often used for signs and pamphlets, as well as a visually offset style contrasted to Mincho (performing the same role italic scripts do for most Western languages).
To show the difference, let us look at two images using minchou and gothic versions of the kaisho typeface. These examples use the いろは poem as text, which can be considered a Japanese equivalent of an alphabet song, containing each basic syllable only once (although some are voiced). Observing the "proper" writing style and reading top-down, right to left, this poem is written as follows:
いろ色はにほ匂へど
ち散りぬるを
わ我がよ世たれ誰ぞ
つね常ならむ
うゐ有為のおくやま奥山
けふ今日こ越えて
あさ浅きゆめ夢み見じ
ゑ酔ひもせず
There are many translations possible, given the classical nature of the poem. However, a translation offered by professor Ryuichi Abe in his 1999 work "The Weaving of Mantra: Kûkai and the Construction of Esoteric Buddhist Discourse", published by Columbia University Press, is as follows:
Although its scent still lingers on —
the form of a flower has scattered away.
For whom will the glory —
of this world remain unchanged?
Arriving today at the yonder side —
of the deep mountains of evanescent existence,
we shall never allow ourselves to drift away —
intoxicated, in the world of shallow dreams.
Written in Mincho and gothic styles, this poem looks like:


In addition to the kaisho style, there are the two "cursive" styles called gyousho, ぎょうしょ行書, and sousho, そうしょ草書, which are "simplified" forms of written Japanese. The simplification here refers to the fact that these two styles connect many strokes into single strokes, or in extreme cases, even simplify entire kanji to single strokes. However, this does not make them simpler to read - far from it, the simplifications can make it much harder to tell certain kanji apart, or look up in a dictionary.
Gyousho is usually associated with handwriting: while we can all write letters the way they come rolling out of a printer, we have a special way of writing everything if we do it by hand, and in Japanese this is expressed through a slightly more flowing form of kanji and kana, connecting strokes but, quite often, preserving most of the looks of a kanji. Sousho, on the other hand, is the highly stylised simplifications associated with brush calligraphy — shapes are simplified according to reasonably rigid rules, but these simplifications look drastically different from the original shape, and certain shapes are simplified in such a way that it is nearly impossible to tell one from another without having received some form of education in reading and writing brush calligraphy. Illustrating this again using the いろは poem:


Lastly, there are two "traditional" styles that you only find used in very specific applications: reisho, れいしょ隷書, "square style" or "block style", and tensho, てんしょ篆書, "seal style". These two styles are not just traditional but "ancient" styles, in that they are styles found used far back in Japanese history on official records and seals (respectively). Reisho is associated with the style of carved kanji on woodblocks (explaining its 'block style' name), and is still in use today for things such as traditional signs. Tensho is also still used in modern Japan, featuring most prominently in personal stamps — in Japan, you do not sign documents with a signature, but you put your personal stamp on the document. Everyone who has ever signed something has one of these, and you'll probably know them from the distinctive red-ink kanji-in-a-circle or kanji-in-a-square signs on Chinese and Japanese paintings and brush works. Illustrating these two styles using the いろは again:


Special dictionaries exist that list kanji in their different forms. These come in the form of santaijiten, さんたいじてん三体辞典, which list kaisho, gyousho and sousho forms ("santai" meaning three forms), and gotaijiten, ごたいじてん五体辞典, which list all five forms for a kanji ("gotai" meaning five forms). There are even reference works which don't so much list the forms in a neatly ordered fashion, but show you different interpretation that artists have of the gyousho and sousho forms of kanji, which makes them more "artbook" than reference book, even when they are invaluable resources to students of Chinese and Japanese calligraphy.
Words and word classes
With all this talk about lettering, one would almost forget that just letters hardly get us anywhere if we don't know any words to write with them. However, Japanese doesn't have quite the same words as most western languages have. You may have heard the terms "noun" and "verb", and you may even be familiar with terms like "prepositions" and "adverb", but there are quite a number of these word types, and we'll look at all of these in terms of whether or not Japanese uses them, and what they look like.
Articles
This is a group of words that you rarely think about as real words: in English, "the", "a" and "an" are articles:. They precede a word to tell you whether it's an undetermined 'something' (by using "a" or "an") or a specific 'something' (by using "the"). Japanese, on the other hand, doesn't have articles at all. It's not just that it uses a different way to indicate the difference between for instance "a car" and "the car": there are no simple words you can use to show this difference. This might sound like a rather big stumbling block, but there are many languages which do not have articles, and the people that use those languages can get the meaning across just fine without them - as we will see when we talk about context later in this chapter.
Verbs
Verbs are words that represent an action either taking place or being performed, and can be modified to show things like negatives or past tense. In English, words like "fly" and "float" are verbs for actions that are being performed, and we can make them negative or past tense: "not fly", "not float", "flew" and "floated" respectively. Similarly, words like "walk" and "eat" are verbs for actions that can be performed, and we can make them negative or past tense too: "not walk", "not eat", "walked" and "ate" respectively. Verbs also have a regularity: walk and float are regular verbs in that they follow the same rules: past tense is "... + ed", but "fly" and "eat" are irregular: they do not become "flyed" and "eated", but "flew" and "ate".
Finally, verbs can be transitive, or intransitive. The verb "walk", for instance, is something that you just do. You walk. When you see this kind of construction in a sentence, we say that the verb is used "intransitively" - in contrast, "eat" is a verb you can either use intransitively ("What are you doing?" - "I'm eating") or transitively: "I eat an apple". In this use, you're applying the verb's action to something: "I throw the ball", "I eat an apple", "I fly a plane" are all examples of this. However, there is something funny about transitivity: some verbs, like "walk", you can only use intransitively (we don't say that we "walked the street", for instance), but many verbs can be used either intransitively or transitively, like "eat".
There are also a number of verbs that can only be used transitively, but these are special verbs, typically called auxiliary verbs. In English, "have" and "want" are examples of these. Without an additional "something", these verbs do not have any meaning on their own: saying "I have." or "I want." is grammatically incorrect. At the very least, you'd need to say something like "I have it." or "I want that." for the verbs to be used correctly.
Japanese verbs are characterised by a high degree of regularity as, except for three verbs, all verbs are regular. These regular verbs fall into two categories, namely the "five grade" verbs called godan, ごだん五段, and the "single grade" verbs, called ichidan, いちだん一段. These two categories inflect (take on different tense, mood, etc) in the same way on almost all possible inflections, but of course differ on some (otherwise there wouldn't be two categories, but just one).
With respect to transitivity, Japanese verbs can be a little problematic. Rather than being labelled intransitive or transitive, Japanese verbs are labelled as being じどうし自動詞 or たどうし他動詞, literally "verb that works on its own" and "verb that works paired with something". Quite often these two verb classifications map to the roles of "intransitive" and "transitive", respectively, but sometimes they don't. For instance, traversal verbs (such as 'walk', 'run', 'fly', 'sail', etc.) are intransitive in English, but are 他動詞 in Japanese: they can be used with an object to indicate what is being walked or run over, what is being flown through, what's being sailed in, etc. As such, while in English one does not "fly the sky" or "swim the ocean" (at the very least you'd need a preposition such as "through" or "in" to make those correct English), in Japanese this is exactly what you're doing.
自動詞 on the other hand do not have a "verb object"; they operate on their own. For instance, in English we can say "I understand the text", and if we look at the sentence from a grammatical point of view we can say that 'the text' may be considered the verb object for the verb 'understand'. However, in Japan the verb for understanding, わ分かる, is a 自動詞 verb, and so even though you're used to thinking of "understanding" as a transitive verb action, you suddenly have to get used to it being an intransitive verb action in Japanese. Particularly at first, this can be somewhat confusing, but like all foreign languages, exposure to frequently used verbs means you'll quickly develop a sense of how to use them properly (even if you can't remember the terms 'intransitive', 'transitive', 自動詞 and 他動詞!).
Nouns
Nouns are words that are used to name "somethings", although those somethings don't need to be things you can actually hold in your hand and look at: "car", "New York", "magnification" and "ambiguity" are all nouns, but while you can touch a car, or point at New York, it's impossible to point at something and go "that is magnification" or "that is ambiguity". A good rule of thumb is "if you can say it's 'something else', it's a noun":
"This car is old."
"New York is hot."
"The magnification is high."
"This ambiguity is omnipresent."
These are all examples where the noun is said to be something else (and that something else is known as an "adjective"). This even works with things that you might think are verbs, but actually aren't: "walking" for instance looks like it's a verb, because "walk" is a verb, but there are instances when "walking" is most definitely a noun. Of the following two sentences, the first uses "walking" as a verb, while the second uses "walking" as a noun:
"I went to work walking."
"I like walking."
We can verify that in the first sentence we're using a verb, and in the second a noun, by replacing "walking" with a word which we know is a noun, like "cheese":
"I went to work cheese."
"I like cheese."
The first sentence suddenly makes no sense at all anymore, while the second sentence is still perfectly fine. This "words can belong to multiple classes, and which it is depends on how it's used in a sentence" is something quite important to remember when dealing with Japanese, as well as learning foreign languages in general.
As a last bit of noun related information, in Japanese (as in English, in fact) nouns do not inflect. They usually need verbs to indicate negative, past tense, and other such things: in English we can say "This is not a book" or "This was a book", but the negative and past tense comes from inflections of the verb "be", not the noun itself.
Pronouns
There is a special class of words called "pronouns" in English, which act as if they're nouns, but are used to replace nouns in sentences. The best known pronoun in the English language is the word "it", but words like "this", "that" as well as "you" or "we" are all examples of pronouns. Rather than constantly referring directly to what we're talking about, it is far more natural to use pronouns instead:
"I bought a really good book. I had already read it, having borrowed it from the library last month, but I saw it in the book store on discount, so I decided to buy it."
In this sentence, the pronoun "it" is used quite a number of times, replacing "the book" at every instance:
"I bought a really good book. I had already read the book, having borrowed the book from the library last month, but I saw the book in the book store on discount, so I decided to buy the book."
This sounds unnatural to English ears, even though grammatically speaking there is nothing wrong. In Japanese, pronouns are part of a class of words colloquially referred to as "kosoado", こそあど, for the fact that they all start with either "ko-", "so-", "a-" or "do-" depending on their level of proximity (for instance, 'this' vs. 'that') and whether they are stative or interrogative ('that' vs. 'what').
Nominalisers
Japanese has an extra class pertaining to nouns, known as the nominalisers: words that, when used with other words or phrases, turn these words or phrases into something that can act as if the whole construction is a noun. In English, an example of this is the collection of words "the way in which":
"The way in which the government is handling the issue of criminal law is questionable."
In this sentence, "the way in which" is used to turn "the government is handling the issue of criminal law" into a single noun construction. As such we can replace "the way in which the government is handling the issue of criminal law" with a simple pronoun if we wish to talk about it in later sentences:
"The way in which the government is handling the issue of criminal law is questionable. It does not seem to be motivated by sound principles, but by back-office politics."
Japanese has quite a number of these nominalisers, each with its own meaning and nuance, and we shall look at these nominalisers in the chapter on language patterns, too.
Adjectives
As we saw in the section on nouns, any word that can be used to be "more specific" about a noun is called an adjective. Words like "big", "cold", "square" can all be used as adjectives to be much more specific about, for instance, the noun "box":
"This is a box."
"This is a square box."
"This is a big, square box."
"This is a big, cold, square box."
In Japanese, there are two types of adjectives, namely "verbal" adjectives and "nominal" adjectives, the difference being that the first type can — unlike in English — be inflected without relying on a copula verb. In English, we have to say "The car was fast", but in Japanese this "was fast" does not use a copula verb such as 'was', but the adjective itself can convey this meaning. In essence, in Japanese we get something akin to "The car is fast-in-past-tense". The copula stays the way it is, but the adjective itself changes, something which trips up many beginning students of Japanese.
The na-adjectives behave in the same way English adjectives do, needing a copula to change. "It was a square box" is the same in Japanese as it is in English, with "is" becoming "was", and the adjective staying the way it is.
While we can use adjectives to be more specific about a noun, they cannot be used to be more specific about a verb. As an example, in the next two sentences the word "fast" is used as an adjective in the first, but is used as a different kind of word in the second sentence:
"This is a fast car."
"I walked quite fast."
In the first sentence, the word "fast" is used to be more specific about the noun "car", but in the second sentence, the word "fast" is used to be more specific about the verb action "walk". While they look like the same word, their use falls in different word classes. When used to be specific about a noun, a word is called an adjective. When used to be specific about a verb, it's called an adverb.
Adverbs
Using words to be specific about verbs and verb actions is called using them adverbially. In fact, in that sentence the word "adverbially" is an adverb, letting us be specific about the way in which "using" is used. While in English it can sometimes be confusing as to whether a word is being used as an adjective or as an adverb, in Japanese this overlap does not exist: both verbal and nominal adjectives are modified (in different ways) so that they can be used as adverbs instead. Because of this, there is no way to mistake whether a word is used as adjective or adverb when you look at a sentence.
In addition to adjectives-turned-adverb, Japanese also has words that are only adverbs. The most important of these are the quantifiers, which include things like "a lot", "not so much" and "often".
Particles
Japanese has an extra word class that isn't found in most western languages: the particle class. Words in this class fulfil a wide variety of roles: denoting grammar explicitly, adding emphasis, disambiguating, marking how parts of a sentence bear relation to each other, supplying reason, contradiction, logical arguments, you name it — there is probably a particle that can be used for it.
Most particles are suffixes, so that when you use a particle to indicate for instance a contrast between two things, it gets added after the first thing, rather than adding it in front like in English.
English: While (X is the case), (also Y).
Japanese: (X is the case) while, (also Y).
Within this word class, there is an important subclass known as the counters. Like Chinese, but very much unlike most western languages, counting in Japanese requires not just a knowledge of numbers, but also of which particle to use in order to describe the category of things you are counting. In the same way that you can ask for two mugs of beer or two glasses of beer in English, you need to use the counter for "mugs" or "glasses" in Japanese. However, while you can ask for "two teas" in an English establishment, this kind of request is impossible in Japanese. You have to order "two (units of) tea", where the counter that you chose for your units makes the difference between whether you're asking for two cups or tea, two bags of tea, or are accidentally asking for two sheets of tea.
Prefixes
Some particles, as well as some common concept markers, are prefixes rather than suffixes — they are placed in front of words belonging to certain word classes. A handful of special prefixes are used for things like marking words as :honorific, performing "inherent" negation (an English example of which is "the house was windowless" rather than "the house had no windows"), indicating repetitions ("rereading a book") and acting as category marker for categories such as "new", "big" or "most", as well as some more exotic categories such as extents or limits. These will be discussed in detail in the chapter on particles, in the section on prefixes.
Onomatopoeia and mimesis
Two final word classes which are important to know when dealing with Japanese are the onomatopoeia, and the mimesis. Quite a mouthful, onomatopoeia (from the Greek onomato-, "name", and poi- "to make") are words that are used to reflect the sounds that things make. For instance, "The heavy rock splooshed into the lake" is an example of an onomatopoeic verb. It doesn't tell us what the rock actually did — namely, fall into the water — but implies it by virtue of the sound we know a rock falling in water makes: "sploosh".
In addition to such "sound" words, there are also "state" words, which do not indicate a particular sound, but indicate a particular property. Rare in English, an example of this would be the word "gloopy" when describing something. Calling something "gloopy" doesn't tell you something objective about it, but you can surmise it's probably of a viscous liquid gel-like consistency, as well as unpleasant to the touch.
While in English (and in most other western languages) using these words is considered a sign of a poor grasp of the language (after all, why use a word like "gloopy" when you can call something a "liquid, but viscous, unpleasant gel"), and mainly associated with "children's language", in Japanese using onomatopoeia is essential to natural sounding language: with thousands of these words available to choose from, each with its own connotations and implications, picking the right onomatopoeia or mimesis at the right time is something that demonstrates a high level of competency in the language.
Onomatopoeia, called ぎおんご擬音語 ('giongo', in which the 'gi' part means 'to mimic', the 'on' part means 'sound', and the 'go' part means 'word') and mimesis, called ぎたいご擬態語 ('gitaigo', in which 'tai' means condition or state), are some of the hardest words to learn, as they usually carry very specific nuances in meaning. For instance, in relation to a leaking tap, a Japanese person might say "the water was dripping out", picking one specific word from among a great number of possible onomatopoeia to indicate whether the dripping was intermittent or continuous, whether the drips were light or heavy, whether their impact in the sink was almost silent or accompanied by backsplash noises, each of these qualities being represented by a different onomatopoeic word.
Because of this, onomatopoeia and mimesis are an unofficial yardstick when it comes to learning Japanese: if you can use the right onomatopoeic expression at the right time, you have mastered a crucial element to speaking natural sounding Japanese.
Compound words
This is technically not a word class, but a language feature: in some languages several words can be combined into single words with more meaning that just the individual parts. This practice, called compounding, is something that some languages have a knack for, and some languages simply do not bother with. English, for instance, is a language in which compound words are rare — although not unheard of. A common English compound word is the word "teapot", for instance. A combination of the nouns "tea" and "pot", this would have to be a pot for tea. However, it's not really a pot, it's more a decanter. Similarly, the "tea" in question is never dry tea leaf, even though that's also called "tea" in English; it has to be boiled water infused with tea leaf. So, the single compound noun "teapot" has more meaning than if you looked at the meaning of just the two nouns it was built from.
This "joining up two (or more) words to form new, single words" is one of the major dividing lines we can use when trying to classify languages: English is a language sparse in compound words, as are French, Spanish and Italian, but German, Danish, Dutch, Finnish, Polish, Hungarian, Arabian, and also Japanese, are languages in which compound words are frequently used.
In Japanese, nouns are not the only compound words available — compound adjectives as well as compound verbs are also quite common.
Sentence structure
In addition to knowing which word classes are used in a language, we can also look at languages in terms of how sentences are structured. The most simplistic categorisation of languages in this respect is by looking at the "Subject, Object and Verb" ordering. This categorisation looks at how languages order these three words classes, leading to the conclusions that English, for instance, is an SVO language, while Japanese is an SOV language: in English, most sentences are of the form "we do something", where the subject ("we") precedes the verb ("do") which in turn precedes the object ("something") for that verb. Japanese, in contrast, follows a different ordering: most sentences are of the form "we, something do" (with the comma added purely for ease of reading) where the subject precedes the object for the verb, after which the actual verb is used. There are also VSO languages, such as formal Arabic or Welsh, where the sentence structure is predominantly "do, we, something" and VOS languages, such as Malagasi (used in Madagascar) and Fijian (used in Fiji) where the structure is predominantly "do something, we".
However, while this terminology allows us to broadly categorise languages, based on what the 'typically used' pattern looks like, it doesn't tell us anything about how correct or incorrect sentences are if they do not adhere to these S/V/O "rules". For instance, while "we ate some cake" is a normal English sentence, a slightly less conventional but still grammatically perfectly valid English sentence could be "cake; we ate some". This sentence does not fall in the SVO category that is associated with English, but that doesn't mean it's an incorrect sentence — it just means the SVO label doesn't tell the whole story. This becomes particularly apparent when we look at what "minimal sentences" may look like in different languages.
In English, a minimal sentence (that is, one that isn't considered an expression like "hi!" or "hmm") consists of a subject and a verb: "I ate" or "she runs" are examples of minimal sentences. Trying to shorten a sentence further — without making the sentence context sensitive — yields broken English, which is arguably simply not English. This notion of context is important: if we are asked "How many cookies are left?" and we answer with "four", then this "four" is technically a sentence comprised of a single word, and sounds natural. However, if we were to use the sentence "four." on its own, it is impossible to tell what we mean by it. This means that while English is an SVO language, it's really an SV(O) language: you need an S, you need a V, and if you use an O, it comes last, but you're not obliged to have one.
When we look at Japanese we see the S/V/O category crumbling even further. Rather than just being an SOV language, it's actually an (S)(O)V language: You need a verb, but you don't need a subject or object at all to form a correct minimal sentence in Japanese. While in English saying "ate" is considered not enough information to make sense of, Japanese is a language in which competent listeners or readers fill in these blanks themselves, choosing which subject and object make the most sense, given what they know about the speaker. This is what makes Japanese hard: most of the time, in every day Japanese, subjects and objects will be omitted left and right because, as a competent listener, you should know what they should have been — Japanese relies heavily on people's ability to guess what someone else is talking about, something which can only come through regular exposure to, and use of, the language.
Word order
While it's all well and good to know that minimal Japanese is an (S)(O)V language, it's also important to know that in Japanese, grammar is put directly into the sentence through the use of particles. While in English grammar only becomes apparent through the positioning of words, in Japanese words are "tagged", as it were, with their grammatical role. To illustrate this, an example sentence:
きのう昨日はいぬ犬がわたし私のごはん飯をた食べました。
kinou wa inu ga watashi no gohan o tabemashita.
This sentence is composed of several "blocks": 昨日は, 'kinou wa', indicates the noun 'kinou' ("yesterday") as context. In 犬が, 'inu ga', the noun 'inu' ("dog") is marked as verb actor, in 私の, 'watashi no', the noun 'watashi' ("I"/"me") is made genitive (forming "my") and linked to ご飯を, 'gohan o', the noun 'gohan' ("dinner") marked as direct verb object, with the final word 'tabemashita' being the past tense of the verb "eat":
"Yesterday, (a/my/our) dog ate my dinner."
In English, there is very little position variation possible in this sentence: "A dog ate my dinner, yesterday" is still okay, but rearranging the sentence to read "Yesterday, my dinner ate a dog" completely changes the meaning of the sentence from something unfortunate to something unsettling. In Japanese, the explicit presence of grammar markers in a sentence means that rearranging the "blocks" doesn't change the meaning of the sentence at all:
昨日は私のご飯を犬が食べました。
kinou wa watashi no gohan o inu ga tabemashita.
"Yesterday: my dinner, (a/my/our) dog ate."
私のご飯を、昨日は、犬が食べました。
watashi no gohan o, kinou wa, inu ga tabemashita.
"My dinner — yesterday — (a/my/our) dog ate."
昨日は犬が食べました、私のご飯を。
kinou wa inu ga tabemashita, watashi no gohan o.
"Yesterday (a/my/our) dog ate; my dinner."
食べました、犬が、私のご飯を、昨日は。
tabemashita, inu ga, watashi no gohan o, kinou wa.
"Ate, a dog (did), my dinner, yesterday."
All of these are perfectly valid sentences in Japanese, because all the words with meaning are explicitly tagged with the role they play in the sentence. While some of these sentences will sound more usual than others, they all mean the same thing. However, once we start moving the particles around, pairing them with words from different blocks, the same problem arises as we saw for English:
昨日は(犬が)(私のご飯を)食べました。
kinou wa inu ga watashi no gohan o tabemashita
"Yesterday, (a/my/our) dog ate my dinner."
昨日は(ご飯が)(私の犬を)食べました。
kinou wa gohan ga watashi no inu o tabemashita
"Yesterday, (the) dinner ate my dog."
In summary, it is not so much word order that inherently gives meaning to a sentence in Japanese, but the 'semantic blocks' of words, paired with specific particles. Their combination tells you what the block means, and what role it plays in a sentence. As long as the pairings are preserved, you can order these blocks in any way you like and maintain the same sentence meaning. Which blocks go where, finally, depends entirely on what you believe is the most important bit of the sentence, as is highlighted in the next section.
Emphasis
Another feature of languages is where emphasis lies in a sentence. In English, we tend to put the most pressing bit of information early in the sentence, and then say whatever is further relevant to this information later in the sentence. The previous sentence is a good example of this: the main point is that "important information comes early", which is found earlier in the sentence than the additional information. In Japanese, things are the other way around: the more important the information is, the later it will be placed in a sentence.
A rather simple example is the following pair of sentences:
"I fell off my bike while riding home today."
きょう今日はじてんしゃ自転車でかえ帰りちゅう中でころ転んでしまいました。
kyou wa jitensha de kaerichuu de korondeshimaimashita.
While the English sentence is up front with the emphasis, namely that we fell off our bike, the Japanese sentence doesn't actually tell you what happened until the very last word, 'korondeshimaimashita' — "(I) (regrettably/unfortunately) fell down".
Being unfamiliar with this difference in emphasis (point, then details in English vs. details, then point in Japanese) can lead to confusion when dealing with words in which this ordering is important, such as indicating simultaneous actions: in English, "while". If someone asks "what are you doing?" and we answer with "eating some dinner while watching TV", then the main activity is eating dinner. The "watching TV" is additional information, but not strictly speaking required for the answer to be complete. In Japanese, with the same core information and details used, the placement is opposite: the Japanese answer "terebi o minagara, gohan o tabemasu" lists "watching TV" first ('terebi o mi-'), then adds the marker for simultaneous action ('nagara') and then concludes with "eating dinner" ('gohan o tabemasu'). Both in English and Japanese, the concise answer would simply have been "eating dinner", or "gohan o tabemasu".
Another, more common example is the use of "rather": "I would rather have X than Y" is a well known sentence pattern in English, listing the thing with most preference first. This becomes even more obvious in the shortened pattern, "I would rather have X". In Japanese, the 'rather' construction uses the particle 'yori' and, like before, the order is quite opposite:
Y yori X no hou ga ii to omoimasu
Trying to project the way 'rather' works in English onto what 'yori' means can easily lead to confusion: the English word 'rather' assumes that the most important bit is on the left, so if we think 'yori' does the same — because we know it can be translated as 'rather' — we might mistakenly believe that this sentence says "I would rather have Y than X", instead of what it really means, "I would rather have X than Y". While potentially confusing at first, this reversal of placement for emphasis becomes more intuitive the more one practises Japanese.
However, having important information at the end of a sentence leads to a unique problem when interpreting or translating Japanese: how does one deal with trailing sentences? In English, when the latter part of a sentence is left off, the most important information has already been presented, so when the sentence is cut off we might be missing the details, but only the details. In Japanese, and other languages where more important information comes later in the sentence, leaving off the latter part of a sentence leaves a reader or listener with the details, but no knowledge of what these details actually apply to!
While, of course, this doesn't lead to problems for people who grew up using a language in which emphasis comes later in a sentence, this 'feature' can be a great pain for people who grew up with "important bits first". To them, it feels very much like the language is based on the concept of "filling in the blanks", without any indication of what can be used to fill them in. Sadly, this too can only be remedied through continued exposure to, in this case, Japanese, so that one becomes intuitively familiar with which words might be implied if they're left off.
Pitch and accents
Linguistically speaking, Japanese - like various other Asian languages such as Thai or Chinese - uses syllable pitch to place accents in words. Quite often you will find this explained as Japanese being a language with two pitch levels, high and low, which makes it relatively easy to learn compared to a more complicated language (in terms of pitch) such as Chinese, which has four pitch levels for Mandarin, and at least six for Cantonese. However, this creates the false impression that there are only two tones at which you should pronounce Japanese, which is simply not true. Instead, accent through pitch in Japanese is best described in terms of tone difference:
- If a word has its accent on the first syllable, then the pitch of the word starts at a high tone and then drops in pitch at the second syllable. After this, the pitch may remain either constant, or (slowly) go down as the rest of the word is pronounced. Due to this relatively large difference between the first and second syllable, the first syllable is considered accented by the Japanese ear.
- If a word has its accent on a syllable other than the first or the last, the pitch may remain constant or rise gradually until the syllable after the one that is accented, where the pitch goes down suddenly to create the pitch difference that is considered an accent in Japanese.
- If a word has its accent on the last syllable, the pitch may remain constant or rise gradually until the last syllable, which is pronounced at a notably higher pitch, marking it as accented to the Japanese ear.
- If a word has no accent, the pitch may remain constant or rise gradually. This covers the majority of Japanese words and while the pitch may change, the lack of sudden discontinuous change makes this sound unaccented to the Japanese ear.
The presence and order of pitch change can make the difference between rain (雨) and candy (飴), both pronounced "ame" but with their accents on the first and second syllable respectively, or more drastically between an umbrella (傘) and syphilis (瘡), both pronounced "kasa" but again with their accents on the first and second syllable respectively.
For sentences, too, pitch plays an important role. A sentence ending with a high and then a low syllable, compared to the same sentence ending with the last two syllables in neutral pitch, will be experienced as a question rather than as a statement, for instance. Anger, lecturing, boredom, and a wide variety of emotions can be told from the pitch pattern of a sentence, not unlike in most Western languages. However, while in western languages pitch only adds emotion, in Japanese, a misplaced pitch may also change the meaning of the words being used.
Gender roles
Due to the different formality levels in Japanese, a particular style of speech is often associated with a particular gender — the more polite and reserved being associated with female, and the more brash and forward plain being associated with male. While this is an understandable association, the problem with associating speech patterns with genders is that people often mistakenly apply backward logic: if the female speech pattern is reserved, then reserved speech is female speech.
This isn't how it works, though. Typically, speech patterns fall into categories such as polite reserved speech, plain informal speech or honorific, which are used by a particular gender more than the other by virtue of statistics. However, this does not mean that what is considered "female speech" is never used by men, or what is considered "male speech" isn't used by women, as there is no such thing as exclusively male or female speech. A more accurate distinction is to consider speech patterns as direct versus indirect or assertive versus reserved. Women tend to be more reserved and use less direct speech, and men tend to be more assertive and use more direct speech. However, when the situation warrants it, there is nothing to prevent men from using reserved indirect speech, or women from using assertive direct speech. It's all about what the social setting warrants.
This said, there are a few words (not speech patterns) that are genuinely effeminate or masculinemasculine, such as the effeminate dubitative particle かしら, or the masculine personal pronoun おれ俺. It is important to notice that the labels used here are "effeminate" and "masculine", and not "female" and "male". Very effeminate men (such as transvestites or homosexuals) may very well use very effeminate words, and hardcore business ball-busting career women may very well use very masculine words to demonstrate their dominance. Again, it's all about the social setting.
Context language
As mentioned in the section on sentence structure, Japanese is a context sensitive language, relying heavily on the reader or listener to be able to keep track of information during a conversation, and omitting any information once it has become contextual. Before we look at an example of this, we will look at how a "context" differs from a "subject", as this can cause some confusion: in our day-to-day experience of language, the words 'context' and 'subject' refer to the same thing. If a public speaker at some convention is talking about the physics of Star Trek, then we can say that "the subject of his talk is the physics of Star Trek", or that his talk should be interpreted within the context of "the physics of Star Trek", making the two refer to essentially the same idea — a topic.
Grammatically, the terms are much further apart. Rather than both "subject" and "context" being able to refer to some topic, the two mean wildly different things. A "context" is the overall topic of some text or conversation; it doesn't necessarily have to be mentioned, but it is clear what the text or conversation is all about. A "subject", on the other hand, refers to specific words in individual sentences within a text or conversation. The best way to indicate the difference when we use the words "context" and "subject" from a grammatical perspective is as follows:
"A sentence says something about a subject, within a certain context."
For instance, given that this section talks about "context", the sentence "It can be a problematic 'feature' of Japanese for people who only know English" is readily interpreted as meaning "Context can be a problematic 'feature' of Japanese for people who only know English". You know what "it" refers to because of the context you're reading it in. Had this sentence been in a section on the sparsity of language, then you would have understood "it" to refer to "the sparsity of Japanese".
In Japanese, this concept of "sentences say things about subjects within a certain context" is taken further than in English. The following conversation may illustrate this:
A: あたしのコップをみ見かけませんでしたか?
B: ああ、み見てません。
A: おかしいわ。ついさっきまでも持ってたんですけど。
B: いま居間のテーブルにお置いてきてしまったのではないでしょうか。
A: あっ......そうかもしれません、ね。
Transcribed, this reads:
A: atashi no koppu o mikakemasen deshita ka?
B: aa, mitemasen.
A: okashii wa. tsui sakki made mottetandesukedo.
B: ima no teeburu ni oitekiteshimatta no dewanai deshou ka.
A: a... soukamoshiremasen, ne.
This conversation can be translated to natural sounding English in the following manner:
A: "You haven't seen my cup, have you?"
B: "No, I haven't seen it."
A: "That's odd. I just had it a moment ago."
B: "Perhaps you left it on the table in the living room?"
A: "Ah! That might be."
In this translation there are a number of contextual simplifications: "you" has been used to refer to a specific person, "it" has been used to contextually refer to the cup in question, and "that" has been used by speaker A to refer to what speaker B said. In Japanese, rather than using contextual words like this, they are simply omitted entirely. If we do a literal translation to English, we see a rather different, context-heavy kind of conversation:
A: "Haven't seen my cup?"
B: "Indeed, haven't seen."
A: "Odd... had just a moment ago."
B: "Could be left on living room table?"
A: "Ah! Might be so."
It's not just "it" which has been omitted, even personal pronouns are typically left out. This makes for a seemingly very sparse language, which can be hard to interpret, especially when one is just starting out with the language. For this reason, some textbooks and courses will present Japanese sentences with all the contextual information in them — while this does not violate Japanese grammar, it does lead to highly artificial sentences, existing only in textbooks rather than reflecting the language as it is actually used. Because of this, all the examples in this book will try to use "natural" Japanese phrases, with contextual words required for the sentence to make sense in translation added in parentheses. For instance:
A: okashii wa. tsui sakki made mottetandakedo.
A: (That's) odd. (I) just had (it) (a) moment ago.
And with that, we are finally able to move on from introductory text to the language itself: let's sink our teeth in some grammar!